
The Natural Language Toolkit is an excellent resource for bare-bones named entity recognition (NER).
This page will help you get the toolkit up and running and give you some basic code for extracting entities from your documents.
Setting NLTK Up
There are lots of online resources on how to get NLTK running on your computer. You don't need to follow my approach, which wraps the project in a virtual environment. If you feel that a virtual environment is too much of a bother—that is, if you only want to run the sample code I provide below—it should be fairly easy to find another tutorial for the NLTK installation, after which the sample code I provide will run just as well as it does when you do your setup the way I describe below.
Create a Virtual Environment
You don't have to create a virtual environment to try out NLTK. But I think you should, especially if you already have a Python project on your machine. See my Using virtualenv for an easy way to do this.
Install NLTK
Assuming you have a working virtual environment, activate it before you install NLTK.
$ source venv/bin/activate (venv) $ pip install -U nltk Collecting nltk Requirement already up-to-date: six in ./venv/lib/python3.4/site-packages (from nltk) Installing collected packages: nltk Successfully installed nltk-3.2.2
Install nltk_data
NLTK offers a huge number of natural language processing resources. Because they can take up so much disk space, you probably don't want to download all the resources onto your computer. For the same reason it makes sense for different projects to share the resources you do need.
To get just the resources you need, and to share them between your projects, take these steps. Inside the project where you've just installed NLTK, and with your virtual environment activated, start up Python and start the NLTK data download process.
(venv) $ python Python 3.4.3 (default, Jun 1 2015, 09:58:35) [GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import nltk >>> nltk.download() showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
Somewhere on your machine a new window should open up, though it might be covered by some other application, if not the terminal your working in. Open that window. The NLTK Downloader may look primitive, but it does work. If you ever get a Resource ... not found message for NLTK, this is how you'll do the fix.
Unless you're very sure of what you're doing, you should probably accept the default download directory (but you could change it by clicking on the File menu). Click on the Models tab. Your window should look something like the image below, though if you're new to NLTK most or all of the lines will be white instead of red or green.
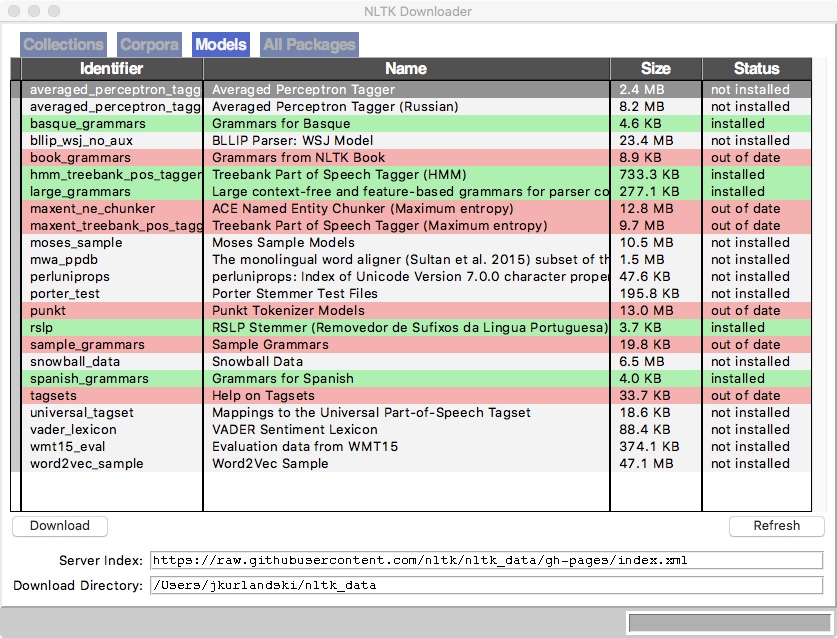
You can see in the figure above that on my system I have a number of models which have been installed: those which are in green are current, those in red are out of date. These are the most commonly used resources. You could download just these to run this sample code. On the other hand, the file size of all of the models is small enough that you might as well download them all. (Other NLTK data, such as the corpora, are the ones that take up a huge amount of disk space.)
Select a model, then click on the Download button to download it. Its status will change to "installed" and its color to green. (By the way, I have not figured out a way to download more than one model at a time.)
When you're finished, click on Python > Quit Python at the top. You should return to your command line, with the virtual environment still activated. If you see error messages, in my experience you can ignore them.
Other Dependencies
Chances are that your NLTK install did not also install numpy, a Python package for scientific computing. You can wait for a ImportError: No module named 'numpy' error message, or install the package in advance.
$ ls
venv
$ source venv/bin/activate
(venv) $ pip install numpy
Collecting numpy
Downloading numpy-1.12.0-cp34-cp34m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl (4.4MB)
100% |████████████████████████████████| 4.4MB 279kB/s
Installing collected packages: numpy
Successfully installed numpy-1.12.0
(venv) $
Sample Code
Here's some code that, while it may be imperfect, will get you started with exploring named entity recognition with NLTK.
NLTKWrapper
I've bundled the basic NLTK code for named entity recognition into a class called NLTKWrapper.
import nltk class NltkWrapper(object): """Provides a simple interface to the NLTK resources required for named entity extraction. Initializes all the necessary resources only once, no matter how many documents are processed. Holds intermediate results as properties to allow separate analysis/debugging.""" # TODO: Are there other options? Will any produce better results? # Initialize the components statically. language = 'english' chunker_pickle = 'chunkers/maxent_ne_chunker/english_ace_multiclass.pickle' sentTokenizer = nltk.load('tokenizers/punkt/{0}.pickle'.format(language)) chunker = nltk.data.load(chunker_pickle) def __init__(self): # Initialize all properties. self.text = None self.sentences = None self.tokens = None self.posTags = None self.parsedInput = None def process(self, inText): self.text = inText self.sentenceTokenize() self.wordTokenize() self.doPosTagging() self.parseInput() return self.parsedInput def sentenceTokenize(self): """ Split the text into sentences. """ self.sentences = NltkWrapper.sentTokenizer.tokenize(self.text) def wordTokenize(self): """ Split the text into tokens. """ tokens = [] for sentence in self.sentences: sentenceTokens = nltk.tokenize._treebank_word_tokenize(sentence) tokens.extend(sentenceTokens) # This list of a list looks buggy, but it seems to be correct. self.tokens = [tokens] def doPosTagging(self): """ Tag tokens for part of speech. """ self.posTags = [nltk.pos_tag(token) for token in self.tokens] def parseInput(self): """ Perform NER. Not traditional parsing. """ self.parsedInput = NltkWrapper.chunker.parse_sents(self.posTags) def getParse(self): strResult = '' treeResult = [] for element in self.parsedInput: strResult += str(element) + '\n' treeResult.append(element) return treeResult, strResult def printParse(inputStr): wrapper = NltkWrapper() wrapper.process(inputStr) trees, treeStr = wrapper.getParse() print('Input:') print(' ' + inputStr + '\n') print('Sentence:') for sentence in wrapper.sentences: print(' ' + sentence) print('') print('Parse as Tree:') print(trees) print() print('Parse as string:') print(' ' + treeStr) print() if __name__ == '__main__': # View the NLTK parse of various inputs. printParse("Mary Jones") printParse("John Smith wrote to Mary Jones.") printParse("John Smith wrote to Mary Jones. Jim Miller wept.") printParse("The man who lives in the blue house dislikes the Martha Cumminham who lives in San Francisco.") printParse("I want to find a new hybrid automobile with Bluetooth.") pass
NltkEntityExtractor
If you run NLTKWrapper and inspect the output for one of the sentences containing the person "John Smith," you'll see that the extractor doesn't always combine first and last names into a single person.
(S (PERSON John/NNP) (PERSON Smith/NNP) wrote/VBD to/TO (PERSON Mary/NNP Jones/NNP) ./.)
You see in the tree above that NLTK collapses "Mary Jones" under a single Person node, but not so for the words "John" and "Smith." For this reason we need a class whose primary purpose is to combine consecutive words of the same entity type into a single entity. This class offers a couple of other advantages as well, including the fact that it can hide from the user the inner workings of NLTK.
from NltkWrapper import NltkWrapper class NltkEntityExtractor(object): """ Provides an interface for NLTKWrapper, extracting named entities from the latter's output. """ IgnoredNodeLabels = ['S'] def __init__(self): """""" self.reinitialize() # Input text currently being processed. self.text = '' # An intermediate result. self.parseTrees = [] # Final output. self.entities = {} def reinitialize(self): """ Reinitialize this object's properties for a new sentence.""" self.parseTrees = [] self.entities = {} def readInput(self, inputStr): """ Submit the input string to NLTK. Process the result into entities held in self.entities. """ self.reinitialize() self.text = inputStr wrapper = NltkWrapper() parsedInput = wrapper.process(inputStr) for tree in parsedInput: self.parseTrees.append(tree) self.extractEntityNames(tree) return self.entities def extractEntityNames(self, tree): """ Process the NltkWrapper tree, loading self.entities with the entities found. Combines two successive entities of the same type into one. """ # TODO: This method is more complex than it needs to be--it doesn't have to be recursive since all # nodes are just one level down. if hasattr(tree, 'label') and tree.label: if tree.label() not in NltkEntityExtractor.IgnoredNodeLabels: if not self.entities.get(tree.label()): self.entities[tree.label()] = [] self.entities[tree.label()].append(' '.join([child[0] for child in tree])) else: lastChild = None for child in tree: if lastChild and self.isSameEntityType(lastChild, child): # print "Same: " + str(lastChild) + "; " + str(child) # Append the new entity to the list. self.extractEntityNames(child) # Now merge last two elements of entities list. entityType = child.label() entityList = self.entities[entityType] # Remove the last two. last = entityList[-1] penultimate = entityList[-2] entityList = entityList[:-2] mergedString = ' '.join([penultimate, last]) entityList.append(mergedString) # Update the object self.entities[entityType] = entityList else: self.extractEntityNames(child) lastChild = child @staticmethod def isSameEntityType(child1, child2): result = False if hasattr(child1, 'label') and child1.label: if hasattr(child2, 'label') and child2.label: if child1.label() == child2.label(): result = True return result def getNerEntities(self): """ :return: a list of entity type-entity pairs """ result = [] for key in sorted(self.entities.keys()): for content in self.entities[key]: result.append((key, content)) return result if __name__ == '__main__': extractor = NltkEntityExtractor() extractor.readInput("John Smith wrote to Mary Jones.") # Print an intermediate result. print(extractor.parseTrees) print(str(extractor.getNerEntities()))
You see that the extractEntityNames( ) method has a TODO comment. The code works fine as it is, but it does a little more work than is necessary. I'm not sure how I ended up writing that recursive block under the TODO, and at the moment I don't have time to clean it up. So let's make that your homework assignment.
External Resources
Some useful links:
- Natural Language Processing with Python by Steven Bird, Ewan Klein, and Edward Loper, aka "The NLTK Book"
- Chapter 7 offers a very good introduction to NER in Section 5—search for "Named Entity Recognition".
- Installing NLTK
- Installing NLTK Data